Профессия data scientist
Содержание:
- *2020: Академия больших данных MADE и HeadHunter выяснили, как меняется спрос на Data Scientist в России
- Что такое Data Science?
- 3 этап: юность
- Как им стать
- Программная инженерия более передаваема
- Как он это делает?
- Курсы или халява?
- Профессия Data Scientist от Skillbox
- Профессия «Data Scientist: анализ данных» от Skillbox
- В этой индустрии царит политика
- Какие языки стоит изучить
- Этап 3. Базовые понятия и классические алгоритмы машинного обучения
- Пример: профилактика диабета
- Зарплата data scientist
*2020: Академия больших данных MADE и HeadHunter выяснили, как меняется спрос на Data Scientist в России
16 июля 2020 года Академия больших данных MADE от Mail.ru Group и российская платформа онлайн-рекрутинга HeadHunter (hh.ru) составили портреты российских специалистов по анализу данных (Data Science) и машинному обучению (Machine Learning). Аналитики выяснили, где они живут и что умеют, а также чего ждут от них работодатели и как меняется спрос на таких профессионалов.
Академия MADE и HeadHunter (hh.ru) проводят исследование уже второй год подряд. На этот раз эксперты проанализировали 10 500 резюме и 8100 вакансий. По оценкам аналитиков, специалисты по анализу данных — одни из самых востребованных на рынке. В 2019 году вакансий в области анализа данных стало больше в 9,6 раза, а в области машинного обучения – в 7,2 раза, чем в 2015 году. Если сравнивать с 2018 годом, количество вакансий специалистов по анализу данных увеличилось в 1,4 раза, по машинному обучению – в 1,3 раза.

Активнее других специалистов по большим данным ищут ИТ-компании (на их долю приходится больше трети – 38% – открытых вакансий), компании из финансового сектора (29% вакансий), а также из сферы услуг для бизнеса (9% вакансий).
Такая же ситуация и в сфере машинного обучения. Но здесь перевес в пользу ИТ-компаний еще очевиднее – они публикуют 55% вакансий на рынке. Каждую десятую вакансию размещают компании из финансового сектора (10% вакансий) и сферы услуг для бизнеса (9%).
С июля 2019 года по апрель 2020 года резюме специалистов по анализу данных и машинному обучению стало больше на 33%. Первые в среднем размещают 246 резюме в месяц, вторые – 47.

Самый популярный навык — владение Python. Это требование встречается в 45% вакансий специалистов по анализу данных и в половине (51%) вакансий в области машинного обучения.
Также работодатели хотят, чтобы специалисты по анализу данных знали SQL (23%), владели интеллектуальным анализом данных (Data Mining) (19%), математической статистикой (11%) и умели работать с большими данными (10%).
Работодатели, которые ищут специалистов по машинному обучению, наряду со знанием Python ожидают, что кандидат будет владеть C++ (18%), SQL (15%), алгоритмами машинного обучения (13%) и Linux (11%).
В целом предложение на рынке Data Science соответствует спросу. Среди самых распространенных навыков специалистов по анализу данных – владение Python (77%), SQL (48%), анализом данных (45%), Git (28%) и Linux (21%). При этом владение Python, SQL и Git – навыки, которые практически одинаково часто встречаются в резюме специалистов любого уровня. Опытных специалистов отличают развитые навыки анализа данных, в том числе интеллектуального (Data Analysis и Data Mining).
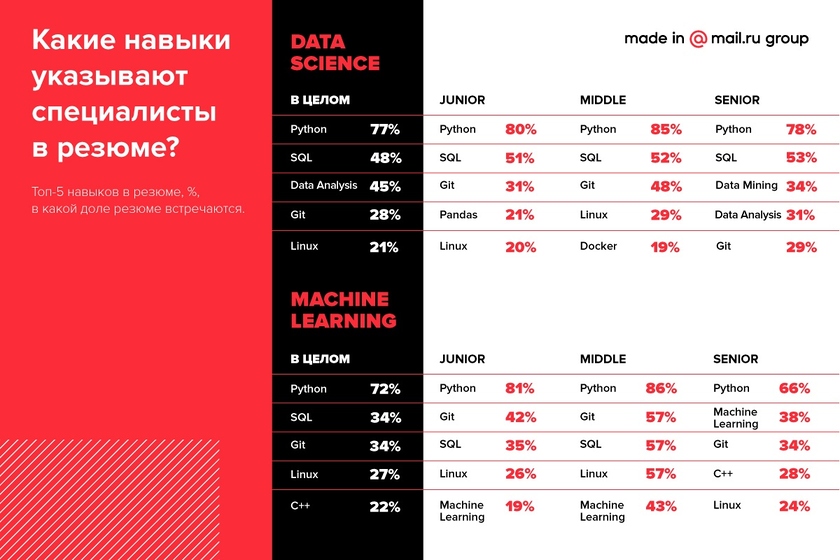
У специалистов по машинному обучению в топе такие навыки, как владение Python (72%), SQL (34%), Git (34%), Linux (27%) и С++ (22%).
На долю Москвы приходится больше половины (65%) вакансий специалистов по в сфере анализа данных и ровно половина вакансий специалистов в области машинного обучения. На втором месте Санкт-Петербург: 15% вакансий специалистов в сфере анализа данных и 18% вакансий в области машинного обучения — в этом городе.
По сравнению с первым полугодием 2019 года в июле 2019 года – апреле 2020 года доля вакансий специалистов по анализу данных в Москве несколько возросла — с 60% до 65%.
Что касается соискателей, больше половины из них также находятся в Москве: 63% специалистов по анализу данных и 53% специалистов по машинному обучению. Вторая строчка – тоже за Санкт-Петербургом (16% и 19% резюме соответственно).
Что такое Data Science?
Пожалуй, самое лаконичное определение, которое мне удалось найти в интернете:

Я думаю, что если найти пересечение различных определений что же такое Data Science, то им будет лишь одно слово — данные. Всё это говорит о том, что широта применения Data Science огромна. Согласитесь, но ведь в этом нет ничего хорошего ни для кого: ни для вас, ни для бизнеса. Эта широта не дает никакой информации о вашей потенциальной деятельности. Ведь с данными можно делать всё, что угодно. Можно строить сложные отчеты или «шатать» таблички с помощью SQL. Можно предсказывать спрос на такси константой или строить сложные математические модели динамического ценообразования. А еще можно настроить поточную обработку данных для высоконагруженных сервисов, работающих в режиме реального времени.
А вообще, причем здесь слово «наука»? Безусловно, под капотом у Data Science серьезнейший математический аппарат: теория оптимизации, линейная алгебра, математическая статистика и другие области математики. Но настоящим академическим трудом занимаются единицы. Бизнесу нужны не научные труды, а решение проблем. Лишь гиганты могут позволить себе штат сотрудников, которые будут только и делать, что изучать и писать научные труды, придумывать новые и улучшать текущие алгоритмы и методы машинного обучения.
К сожалению, многие эксперты в этой области на разных мероприятиях зачастую связывают Data Science в первую очередь с построением моделей с помощью алгоритмов машинного обучения и довольно редко рассказывают самое важное, по-моему, — откуда возникла потребность в той или иной задаче, как она была сформулирована на «математическом языке», как это всё реализовано в эксплуатации, как провести честный эксперимент, чтобы правильно оценить бизнес-эффект
3 этап: юность
На этом этапе вам нужно готовиться к собеседованиям и продолжать изучать новые и углубляться в уже знакомые темы. Если вы чувствуете себя уверенно со всеми темами 2 этапа, то, думаю, вы уже готовы для подачи заявления на невысокие должности. Хотя есть еще несколько моментов, чрезвычайно важных для успешного прохождения собеседования.
Во-первых, личные проекты. Если вы учитесь на программе Data Science, большая часть курсов посвящена выполнению проектов по машинному обучению — они хороши и для практики навыков, и для иллюстрации ваших способностей работодателю. Поэтому я очень советую попробовать себя в сторонних проектах. Самый простой путь — Kaggle. Еще, даже если этого нет в требованиях, не помешает иметь на Github примеры ваших кодов и проектов, чтобы показать их вашему будущему начальству.
Во-вторых, скорее всего вам будут задавать вопросы по SQL. Когда я только начинал работать в GoDaddy, я мало что знал о SQL. К собеседованию я немного полистал W3Schools.com, CodeAcademy и погуглил частые вопросы на собеседованиях по SQL. Зависит от компании но, знания по машинному обучению и программированию в любом случае ценятся больше, чем SQL. Этому довольно легко научиться на работе. Здесь Leetcode.com можно потренироваться в SQL и программировании.
Ну и наконец, к завершению этого этапа вы должны обладать необходимыми знаниями, чтобы разбираться в самых разных темах машинного обучения. На чем именно сосредоточиться — будь это RNN, CNN, NLP или что угодно еще — только ваше дело. Что касается меня, сейчас я пытаюсь разобраться в обучении с подкреплением (reinforcement learning).
Как им стать
Учеба обязательна для этой профессии. Причем учиться надо много, долго и основательно. Для начала надо освоить азы математики, статистики и информатики, а дальше изучить языки программирования, лучше начать с Python.
На блоге iklife.ru собраны лучшие курсы по Python для начинающих и опытных программистов, которые будут полезны при освоении должности Data Scientist.
Также рекомендую вам прочитать следующие книги:
- Брендан Тирни, Джон Келлехер “Наука о данных”
- Кирилл Еременко “Работа с данными в любой сфере”
- Уэс Маккинни “Python и анализ данных”
Куда пойти учиться
Лучшее обучение – это онлайн-обучение. Платформы Skillbox, Нетология, GeekBrains, SkillFactory, ProductStar и Stepik предлагают свои обучающие программы:
- Профессия Data Scientist
- Data Scientist
- Data Science с нуля
Ознакомиться с полным перечнем курсов для Data Scientist можно на нашем блоге.
Уточню, что на этом учеба не должна заканчиваться. Data Scientist – это такая профессия, которая предполагает непрерывное обучение. Даже если вы уже работаете, периодически повышать свой уровень надо обязательно. К тому же выбор достаточно широк – это и онлайн-курсы, и тренинги, и конференции.
Где найти работу
Сложно сказать, где именно искать работу по этой профессии. Не из-за того, что мало мест, а, наоборот, потому что нет такой сферы бизнеса, где нельзя было бы применить талант этого специалиста. Ему доступна как работа в офисе, так и удаленно на дому.
Он востребован в таких областях деятельности как:
- IT-сфера,
- медицина,
- банковские структуры,
- СМИ,
- торговля,
- политика,
- транспортные компании,
- страховые фирмы,
- сельское хозяйство,
- наука,
- метеослужбы.
Как я уже говорила, Data Scientist нужен во многих сферах, где необходимы прогнозы, анализ рисков и поведения клиентов. Поэтому список можно дополнить.
Перед откликом на вакансию надо подготовить резюме. В нем сосредоточиться в первую очередь нужно на математических и IT-навыках, опыте работе, успешных проектах и достижениях. Описание должно получиться кратким, лаконичным и простым. Специалисту надо прикрепить портфолио к резюме.
Учтите, что вакансии на эту должность не всегда называются именно “Data Scientist”. Работодатели могут написать, что требуется IT-аналитик, специалист по анализу систем, аналитик Big Data.
Программная инженерия более передаваема
Предоставляя более комплексный опыт в области технологии, разработка программного обеспечения дает лучшие возможности выхода, когда вы решили, что пришло время перемен.
DevOps, безопасность, интерфейс, бэкэнд, распределенные системы, бизнес-аналитика, инженерия данных, наука о данных…
Я знаю ряд разработчиков, которые перешли от программирования к науке о данных. Если вы пробежитесь глазами по требованиям к специалисту в Data Science, то сразу заметите там массу требуемых навыков программиста:
- Опыт работы с SQL и Python, R или SAS;
- Знание AWS;
- Знание Linux;
- Знание экспериментального дизайна для бизнес-экспериментов;
- Знание систем DevOps, таких как GitLab;
Если вы можете создавать сквозные проекты, то вы также можете сделать как минимум модель для Kaggle. Вы можете взять эту модель, произвести ее, настроить авторизацию и Stripe, а затем начать взимать плату с пользователей за доступ. Это ваш собственный стартап.
Я бы никогда не стал утверждать, что наука о данных не подлежит передаче. Принятие решений на основе данных является по истине убойным навыком. Но это также становится чем-то большим, чем когда-либо, поскольку мы все больше ориентируемся на данные.
Как он это делает?
Задачи аналитику ставит владелец продукта или проектный менеджер. Например, разработать и внедрить какую-то модель на производстве. Владелец продукта оценивает сложность задачи и собирает необходимую для решения команду: дата-сайентист, фронтенд- и бэкенд-разработчики, дизайнер и так далее. Специалистов каждой специальности может быть несколько, а может и ни одного, в зависимости от задачи и предполагаемого решения.
Расскажу, как мы в СИБУРе строим модель. Допустим, мы хотим предсказать факт брака детали по данным с датчиков на производстве.

- Первый этап — сбор данных. Аналитик готовит данные для анализа: выгружает из различных источников, обрабатывает пропуски в данных (значения, которые должны быть, но отсутствуют). На выходе получается таблица.
- Второй этап — предварительный анализ. Бывает полезно нарисовать разные графики и внимательно их изучить. В шутку некоторые аналитики называют это методом «пристального взгляда». Это может дать интересные соображения, помочь выявить странности и много чего еще, что поможет в решении задачи.
- Третий этап — построение признакового описания. Поясню, что это. У нас уже есть таблица с данными от датчиков, но в большинстве случаев этого мало. Необходимо самостоятельно рассчитать некоторые величины, которые могут помочь классифицировать деталь как бракованную.
Например, может быть недостаточно измерить температуру в разных точках детали датчиками. Есть смысл рассчитать среднее арифметическое по всем этим датчикам, а также максимальную, минимальную температуру, разброс температур и много чего еще.
Таким образом, рассчитывая и добавляя новые величины, мы расширяем признаковое описание нашей детали. Именно это описание (набор чисел для каждой детали) мы используем для построения модели. В нашем примере моделью будет являться некоторый алгоритм, который пытается восстановить зависимость между признаковым описанием детали и ответом (есть брак или нет).
В итоге модель обычно представляет из себя код, который может прочитать данные (например, из таблицы Excel или из базы данных), построить предсказания и записать результат (опять-таки в таблицу или базу данных).
Но в таком виде модель еще нельзя считать законченной. Модель должна быть внедрена и работать у заказчика.

Если говорить о конкретных проектах, в которых я принимал участие в СИБУРе, то первой была задача разработки модели для производства изобутилена, которая должна была предсказывать коксование. На решетках реактора образуются углеродные отложения, которые могут решетки повредить.
Помимо самой модели, необходимо было сделать визуализацию предсказаний, которая должна обновляться в реальном времени после каждого пересчета предсказаний, а также реализовать регулярную загрузку актуальных данных в базу для расчета предсказаний. Этой задачей я занимался один, при этом периодически пользовался помощью коллег в некоторых вопросах, связанных с производственной системой хранения данных.
В этом проекте я выступаю уже больше как архитектор и разработчик фреймворка, отвечающего за все вычисления. В то время как мой коллега, тоже аналитик данных, но с профильным химическим образованием, больше решает задачи моделирования, в том числе с использованием химии и физики, хотя это разделение обязанностей весьма условно. Также в этом проекте участвуют фронтенд-разработчики, так как визуальная часть нашего решения достаточно сложна.
Курсы или халява?
Выбор между платными курсами и самостоятельным обучением – это индивидуальное решение для каждого. В случае с наукой о данных, есть очень весомые аргументы «за» и «против» каждого варианта. Так, курсы стоят дорого – выше средней цены по современным профессиям, но вместе с тем, они дают возможность учится у практикующих специалистов, которые смогут на понятных примерах объяснить сложные темы.
С другой стороны, много профессиональной информации есть в открытом доступе, и чтобы ее изучить не нужно тратить сотни тысяч рублей. Но остается вопрос – а сможете ли вы разобраться самостоятельно? Чтобы принять взвешенное решение, советуем изучить нашу статью о плюсах и минусах каждого формата обучения: Дистанционное обучение: плюсы и минусы, возможности и преимущества онлайн-обучения
Профессия Data Scientist от Skillbox
Для анализа больших и неоднородных массивов данных используется технология Big Data. Машинные технологии научились делать выводы и использовать инфографику для визуализации данных. На услуги Data Scientist предъявляют спрос банки, мобильные операторы, производители программных продуктов. Уровень оплаты в Big Data стабильно высок. Обучиться профессии с нуля могут новички, а опытные программисты прокачают свои навыки. Курс от Skillbox задействует разные инструменты — языки кода, фреймворки, библиотеки и базы данных.
Освоение новых знаний происходит в контакте с наставником. Сообщество профессионалов Skillbox даёт обратную связь при выполнении заданий и помогает выпускникам с трудоустройством.
Профессия «Data Scientist: анализ данных» от Skillbox
Сайт — skillbox.ru/course/profession-data-analyst Длительность обучения — 9 месяцев. Стоимость обучения — 59 250 рублей или 2 469 руб. в месяц в рассрочку без первого взноса.
Особенность курса — возможность овладеть профессией даже тем, у кого нет специальных знаний в IT или математике. Программа доступна каждому, кто захочет сменить сферу деятельности и получить навыки в востребованной специальности. Обучение завершает защита дипломных проектов, которые оценивают реальные заказчики — это позволяет получить предложение о работе сразу по окончании курса.
Что входит в программу:
- введение в профессию и язык программирования Python;
- ТВиМС;
- математика для аналитика;
- язык программирования R;
- soft skills для программиста;
- английский язык.
Преподаватели курса — действующие Data Scientist крупный компаний — Рамблера, Киви, ivi, Skillbox и других, обладающие опытом в обучении студентов.
В этой индустрии царит политика
Проблеме политики уже посвящена одна очень хорошая статья: «Политика – самая сложная вещь в науке о данных». Очень советую ее прочитать. Первые несколько предложений в значительной степени подытоживают то, что я хочу сказать:
Если вы правда думаете, что глубокие знания в области алгоритмов машинного обучения сделают вас самым ценным сотрудником, перечитайте первый пункт этой статьи: ожидания не соответствуют реальности.
Несомненно, влиятельные в бизнесе люди должны хорошо к вам относиться. Вероятно, для этого вам придется заниматься рутинной и несложной работой или развивать простые проекты. Мне приходилось часто это делать на предыдущей работе.
Какие языки стоит изучить
Для работы в сфере научной обработки данных следует изучать языки программирования. Распространены среди новичков Python и R. Также аналитики используют языки Java, SQL, Scala.
Python
Язык создан в 1991 году, в русском языке распространено название питон. Имеет бесплатную лицензию.
Преимущества:
- простота изучения;
- надежность;
- широкое распространение гарантирует поддержку разработчиков.
Среди недостатков пользователи отмечают появление сообщений об ошибках из-за динамичной типизации языка. Для узких целей статистического анализа уступает языку R.
R
Язык программирования R появился в 1995 году. Лицензия бесплатна.
Плюсы:
- многообразие специализированных пакетов с открытым исходным кодом;
- доступность большого числа статистических функций;
- яркая визуализация данных.
Ему присуща медлительность обработки информации.
Этап 3. Базовые понятия и классические алгоритмы машинного обучения
(Этот этап может занять 200-400 ч в зависимости от того, насколько хорошо изначально вы владеете математикой)
Базовые понятия машинного обучения:
-
Кросс-валидация
-
Overfitting
-
Регуляризация
-
Data leakage
-
Экстраполяции (понимание возможности в контексте разных алгоритмов)
Базовые алгоритмы, которые достаточно знать на уровне главных принципов:
-
Прогнозирование и классификация:
-
Линейная регрессия
-
Дерево решений
-
Логистическая регрессия
-
Random forest
-
Градиентный бустинг
-
kNN
-
-
Кластерзиация: k-means
-
Работа с временными рядами: экспоненциальное сглаживание
-
Понижение размерности: PCA
Базовые приёмы подготовки данных: dummy переменные, one-hot encoding, tf-idf
Математика:
-
умение считать вероятности: основы комбинаторики, вероятности независимых событий и условные вероятности (формула Байеса).
-
Понимать смысл фразы: «correlation does not imply causation», чтобы верно трактовать результаты моделей.
-
Мат.методы, необходимые для полного понимания, как работают ключевые модели машинного обучения: Градиентный спуск. Максимальное правдоподобие (max likelihood), понимание зачем на практике используются логарифмы (log-likelihood). Понимание как строиться целевая функция логистической регрессии (зачем log в log-odds), понимание сути логистической функции (часто называемой «сигмоид»). С одной стороны, нет жесткой необходимости всё это понять на данном этапе, т.к все алгоритмы можно использовать как черные ящики, зная только основные принципы. Но понимание математики поможет глубже понять разные модели и придать уверенности в их использовании. Позднее, для уровня senior, эти знания являются уже обязательным:
Без практических навыков знания данного этапа мало повышают ваши шансы на трудоустройство. Но значительно облегчают общение с другими дата-сайентистами и открывают путь для понимания многих дальнейших источников (книг/курсов) и позволяют начать практиковаться в их использовании.
Пример: профилактика диабета
Что, если мы сможем предсказать возникновение диабета и предпринять соответствующие меры заранее, чтобы предотвратить его?
В этом случае мы прогнозируем появление диабета, используя весь жизненный цикл, о котором мы говорили ранее. Давайте рассмотрим различные шаги.
Шаг 1:
Во-первых, мы собираем данные на основе истории болезни пациента, как описано в Фазе 1. Вы можете обратиться к приведенным ниже примерам.
Данные
Как вы можете видеть, у нас есть различные атрибуты, как указано ниже.Атрибуты:
npreg — Количество беременности
glucose — Концентрация глюкозы в плазме
bp — Кровяное давление
skin — Толщина кожи трицепса
bmi — Индекс массы тела
ped — Функция родословной диабета
age — Возраст
income — Доход
Шаг 2:
Теперь, как только у нас появились данные, нам необходимо очистить и подготовить их для анализа.
Эти данные имеют множество несоответствий, таких как отсутствующие значения, пустые столбцы, неожиданные значения и неправильный формат данных, которые необходимо очистить.
Здесь мы организовали данные в одну таблицу под разными атрибутами, что делает ее более структурированной.
Давайте посмотрим на примеры ниже.
Очистка данных
Эти данные имеют много несоответствий.
В столбце npreg слово «one» написано словами, тогда как оно должно быть в числовой форме.
В столбце bp одно из значений — 6600, что невозможно (по крайней мере для людей), поскольку bp не может доходить до такого огромного значения.
Как вы можете видеть, столбец «income» пуст, в этом случае не имеет смысла прогнозировать диабет. Поэтому иметь его здесь избыточно и это нужно удалить из таблицы.
Таким образом, мы очистим и обработаем данные, удалив выбросы, заполнив нулевые значения и нормализуя типы данных. Если вы помните, это наш второй этап, который представляет собой предварительную обработку данных.
Наконец, мы получаем чистые данные, как показано ниже, которые можно использовать для анализа.
Очищенные данные
Шаг 3:
Теперь давайте сделаем некоторый анализ, как обсуждалось ранее в Фазе 3.
Сначала мы загрузим данные в аналитическую песочницу и применим к ней различные статистические функции. Например, R имеет такие функции, как describe, которое дает нам количество отсутствующих значений и уникальных значений. Мы также можем использовать summary функцию, которая даст нам статистическую информацию, такую как средние, медианные, диапазонные, минимальные и максимальные значения.
Затем мы используем методы визуализации, такие как гистограммы, линейные графики, полевые диаграммы (histograms, line graphs, box plots), чтобы получить представление о распределении данных.
Data Science визуализация
Шаг 4:
Теперь, основываясь на представлениях, полученных на предыдущем шаге, наилучшим образом подходит для этой проблемы — дерево решений (decision tree).
Поскольку у нас уже есть основные атрибуты для анализа, такие как npreg, bmi и т. Д., Поэтому мы будем использовать метод обучения с учителем для создания модели.
Кроме того, мы использовали дерево решений, потому что оно учитывает все атрибуты за один раз, например, те, которые имеют линейную связь, а также те, которые имеют нелинейную взаимосвязь. В нашем случае мы имеем линейную зависимость между npreg и age, тогда как существует нелинейная связь между npreg и ped.
Модели дерева решений очень надежны, так как мы можем использовать различную комбинацию атрибутов для создания различных деревьев, а затем, наконец, реализовать ту, которая имеет максимальную эффективность.
Давайте посмотрим на наше дерево решений.
Дерево решений
Здесь самым важным параметром является уровень глюкозы, поэтому это наш корневой узел. Теперь текущий узел и его значение определяют следующий важный параметр. Это продолжается до тех пор, пока мы не получим результат в терминах pos или neg. Pos означает, что тенденция к диабету является положительной, а neg отрицательной.
Шаг 5:
На этом этапе мы проведем небольшой пилотный проект, чтобы проверить, соответствуют ли между собой наши результаты. Мы также будем искать ограничения производительности, если таковые имеются. Если результаты неточны, нам нужно перепланировать и перестроить модель.
Шаг 6:
Как только мы выполним проект успешно, мы будем делиться результатами для полного развертывания.
Data Scientist’у проще сказать, чем сделать. Итак, давайте посмотрим, что вам нужно, чтобы быть им. Data Science требует навыков в основном из трех основных областей, как показано ниже.
Data Science умения и навыки
Как вы можете видеть на приведенном выше графике, вам нужно приобрести различные умения и навыки. Вы должны хорошо разбираться в статистике и математике для анализа и визуализации данных.
Зарплата data scientist
Доходы зависят от опыта, объема работы и региона. Зарплата специалистов по обработке данных в России, согласно информации HeadHunter, достигает 8,5–9 тыс. долларов (543–575 тыс. рублей) в месяц с учетом бонусов.
Data scientist должен иметь обширные знания в разных областях
В США такие сотрудники зарабатывают 110–140 тыс. долларов (7–9 млн рублей) в год, то есть в месяц около 9–11 тыс. долларов (575–703 тыс. рублей).
Сколько получает junior data scientist
Исследовательский центр HR-портала SuperJob приводит более приземленные цифры. Начинающий специалист в Москве, согласно статистике, может рассчитывать на стартовый оклад от 70 тыс. рублей, в Санкт-Петербурге — 57 тыс. рублей. По мере накопления опыта (до 3-х лет) зарплата увеличивается до 110 тыс. рублей в столице и 90 тыс. рублей в Питере.
Зарплаты опытных специалистов
Эксперты SuperJob выяснили, что профессиональный эксперт-аналитик с научными публикациями в Москве зарабатывает около 220 тыс. рублей в месяц, в Санкт-Петербурге — 180 тыс. рублей. По информации JetBrains, ведущего мирового производителя инструментов для работы с современными технологиями, старший специалист по анализу данных в среднем получает 186 тыс. рублей в месяц.
Что нужно знать о data scientist — рассказывает специалист:
В основе data science лежат простые идеи, но на практике обнаруживается множество тонкостей. Поэтому квалифицированные специалисты — это ценные кадры. Но реальная потребность имеется в сотрудниках уровня middle и выше.

