Все что вы (не) хотели знать о data science
Содержание:
- Часть 1. Почему Cognitive Class?
- Дата-сайентисты в облаках
- Как им стать
- Где нужен и какие задачи решает Data Scientist?
- Плюсы и минусы профессии
- Как решать проблему несовпадения ожиданий?
- Требования к специалисту
- Подборка хороших курсов
- Где используется Data Science?
- *2020: Академия больших данных MADE и HeadHunter выяснили, как меняется спрос на Data Scientist в России
- 2017: Высшая школа экономики будет обучать Data Culture на всех программах бакалавриата
Часть 1. Почему Cognitive Class?
По нелепой случайности, я глубоко убежден, что наверняка есть много другого качественного и полезного материала по данной теме, просто это была одна из ссылок и я по ней перешел.
Надо заметить, что в русскоязычном Интернет пространстве ни под новым брендом (Cognitive Class) ни под старым (Big Data University) портал особо не «светится». Скорее всего главная причина – он не переведен на русский язык.
Тем не менее, то что все материалы бесплатные, большая часть курсов базируется на open-source ПО, а по окончании выдают какие-то сертификаты и «бейджи»(о них позже), в сочетании с любопытством сделали свое дело. Ну и как плюс можно потренировать английский.
Дата-сайентисты в облаках
Облегчить и ускорить работу по сбору данных, построению и развертыванию моделей помогают специальные облачные платформы. Именно облачные платформы для машинного обучения стали самым актуальным трендом в Data Science. Поскольку речь идет о больших объемах информации, сложных ML-моделях, о готовых и доступных для работы распределенных команд инструментах, то дата-сайентистами понадобились гибкие, масштабируемые и доступные ресурсы.
Именно для дата-сайентистов облачные провайдеры создали платформы, ориентированные на подготовку и запуск моделей машинного обучения и дальнейшую работу с ними. Пока таких решений немного и одно из них было полностью создано в России. В конце 2020 года компания Sbercloud представила облачную платформу полного цикла разработки и реализации AI-сервисов — ML Space. Платформа содержит набор инструментов и ресурсов для создания, обучения и развертывания моделей машинного обучения — от быстрого подключения к источникам данных до автоматического развертывания обученных моделей на динамически масштабируемых облачных ресурсах SberCloud.

Футурология
«Я бы вакцинировал троих на миллион». Интервью с нейросетью GPT-3
Сейчас ML Space — единственный в мире облачный сервис, позволяющий организовать распределенное обучение на 1000+ GPU. Эту возможность обеспечивает собственный облачный суперкомпьютер SberCloud — «Кристофари». Запущенный в 2019 году «Кристофари» является сейчас самым мощным российским вычислительным кластером и занимает 40 место в мировом рейтинге cуперкомпьютеров TOP500
Платформу уже используют команды разработчиков экосистемы Сбера. Именно с ее помощью было запущено семейство виртуальных ассистентов «Салют». Для их создания с помощью «Кристофари» и ML Space было обучено более 70 различных ASR- моделей (автоматическое распознавание речи) и большое количество моделей Text-to-Speech. Сейчас ML Space доступна для любых коммерческих пользователи, учебных и научных организаций.
«ML Space – это настоящий технологический прорыв в области работы с искусственным интеллектом. По нескольким ключевым параметрам ML Space уже превосходит лучшие мировые решения. Я считаю, что сегодня ML Space одна из лучших в мире облачных платформ для машинного обучения. Опытным дата-сайентистам она предоставляет новые удобные инструменты, возможность распределенной работы, автоматизации создания, обучения и внедрения ИИ-моделей. Компаниям и организациям, не имеющим глубокой ML-экспертизы, ML Space дает возможность впервые использовать искусственный интеллект в своих продуктах, приложениях и рабочих процессах», — уверен Отари Меликишвили, лидер продуктового вправления AI Cloud, компании SberCloud.
Облака помогают рынку все шире использовать платформы для работы с данными, предлагая безграничные вычислительные мощности, подтверждают аналитики Mordor Intelligence.
По мнению экспертов из Anaconda, потребуется время, чтобы бизнес и сами специалисты созрели для широкого использования инструментов DS и смогли получить результаты. Но прогресс уже очевиден. «Мы ожидаем, что в ближайшие два-три года Data Science продолжит двигаться к тому, чтобы стать стратегической функцией бизнеса во многих отраслях», — прогнозирует компания.
Как им стать
Учеба обязательна для этой профессии. Причем учиться надо много, долго и основательно. Для начала надо освоить азы математики, статистики и информатики, а дальше изучить языки программирования, лучше начать с Python.
На блоге iklife.ru собраны лучшие курсы по Python для начинающих и опытных программистов, которые будут полезны при освоении должности Data Scientist.
Также рекомендую вам прочитать следующие книги:
- Брендан Тирни, Джон Келлехер “Наука о данных”
- Кирилл Еременко “Работа с данными в любой сфере”
- Уэс Маккинни “Python и анализ данных”
Куда пойти учиться
Лучшее обучение – это онлайн-обучение. Платформы Skillbox, Нетология, GeekBrains, SkillFactory, ProductStar и Stepik предлагают свои обучающие программы:
- Профессия Data Scientist
- Data Scientist
- Data Science с нуля
Ознакомиться с полным перечнем курсов для Data Scientist можно на нашем блоге.
Уточню, что на этом учеба не должна заканчиваться. Data Scientist – это такая профессия, которая предполагает непрерывное обучение. Даже если вы уже работаете, периодически повышать свой уровень надо обязательно. К тому же выбор достаточно широк – это и онлайн-курсы, и тренинги, и конференции.
Где найти работу
Сложно сказать, где именно искать работу по этой профессии. Не из-за того, что мало мест, а, наоборот, потому что нет такой сферы бизнеса, где нельзя было бы применить талант этого специалиста. Ему доступна как работа в офисе, так и удаленно на дому.
Он востребован в таких областях деятельности как:
- IT-сфера,
- медицина,
- банковские структуры,
- СМИ,
- торговля,
- политика,
- транспортные компании,
- страховые фирмы,
- сельское хозяйство,
- наука,
- метеослужбы.
Как я уже говорила, Data Scientist нужен во многих сферах, где необходимы прогнозы, анализ рисков и поведения клиентов. Поэтому список можно дополнить.
Перед откликом на вакансию надо подготовить резюме. В нем сосредоточиться в первую очередь нужно на математических и IT-навыках, опыте работе, успешных проектах и достижениях. Описание должно получиться кратким, лаконичным и простым. Специалисту надо прикрепить портфолио к резюме.
Учтите, что вакансии на эту должность не всегда называются именно “Data Scientist”. Работодатели могут написать, что требуется IT-аналитик, специалист по анализу систем, аналитик Big Data.
Где нужен и какие задачи решает Data Scientist?
Дата-сайентисты работают везде, где есть большие объемы информации: чаще всего это крупный бизнес, стартапы и научные организации. Поскольку методы работы с данными универсальны, специалистам открыты любые сферы: от розничной торговли и банков до метеорологии и химии. В науке они помогают совершать важные открытия: проводят сложные исследования, например, строят и обучают нейронные сети для молекулярной биологии, изучают гамма-излучения или анализируют ДНК.
В крупных компаниях дата-сайентист — это человек, который нужен всем отделам:
- маркетологам поможет проанализировать данные карт лояльности и понять, каким группам клиентов что рекламировать;
- для логистов изучит данные с GPS-трекеров и оптимизирует маршрут перевозок;
- HR-отделу поможет предсказать, кто из сотрудников скоро уволится, проанализировав их активность в течение рабочего дня;
- с продажниками спрогнозирует спрос на товар с учетом сезонности;
- юристам поможет распознать, что написано на документах, с помощью технологий оптического распознавания текстов;
- на производстве спрогнозирует оборудования на основе данных с датчиков.
В стартапах они помогают разрабатывать технологии, которые выводят продукт на новый уровень: TikTok использует машинное обучение, чтобы рекомендовать контент, а MSQRD, который купил Facebook, — технологии по распознаванию лица и искусственный интеллект.
Пример задачи:
Если дата-сайентисту нужно спрогнозировать спрос на новую коллекцию кроссовок, то он:
- готовит данные о продажах кроссовок за последние несколько лет;
- выбирает модель машинного обучения, которая лучше всего подойдет для этого прогноза;
- выбирает метрики, которые позволят оценить качество модели;
- пишет код модели;
- применяет алгоритм машинного обучения на данных о прошлых продажах;
- получает прогнозные значения и предлагает их менеджерам для принятия решения об объемах производства кроссовок.
Плюсы и минусы профессии
Плюсы:
Высокие зарплаты.
Дефицит специалистов не только в России, но и за рубежом. Из-за того, что компании только начинают понимать ценность таких сотрудников, вакансия редкая, а значит и конкуренция низкая.
Широкое поле для развития в разных технических направлениях. «С навыками дата-инженера можно уйти в MLOps (введение моделей в продакшн). Можно стать DevOps – организовывать работу сервисов. Можно перейти в менеджмент: руководителем группы аналитиков или разработчиков и прокачивать софт-скиллы».
Минусы:
К профессии нет четких и универсальных требований. В вакансиях компании часто взваливают на дата-инженера обязанности коллег дата-сайентистов или аналитиков. Максим поделился своим опытом работы в небольшом стартапе: «Из-за того, что компания маленькая, нет организационных процессов, СЕО мог позвонить мне в девять вечера. И чем больше я делал, тем больше на меня сваливалось. Я шел работать на Python, делать сервисы, работать с разными видами баз данных, а по факту два месяца писал SQL-запросы».
Во время найма не всегда проверяют нужные навыки
Максим обратил внимание на закономерность: «Довольно распространенная практика, что людей тестируют на то, что не показывает их компетенцию. Проверяют знания алгоритмических задач, теории вероятности, которые проходят в техническом университете на первых курсах
Количество задач, которые ты решил по матстату и терверу не показывают, насколько ты умеешь ориентироваться в бизнес-представлениях, общаться с другими людьми, придумывать решение задачи и писать код».
Как решать проблему несовпадения ожиданий?
Алексей Натекин в своем докладе «Чем отличаются data analyst, data engineer и data scientist» нарисовал картинку с распределением Дирихле, то есть с вероятностью вероятностей.

Предположим, что в Data Science существуют три основные компетенции:
-
Математика. Теоретические знания алгоритмов машинного обучения, и математическая статистика для проверки разных статистических гипотез и обработки результатов, а также любые другие фундаментальные знания, которые будут важны в вашей предметной области.
-
Разработка. Всё, что связано с разработкой, инженерными составляющими проекта, DevOps, SysOps, SRE, и прочее.
-
Предметная область. Навыки коммуникации с коллегами и бизнесом, чтобы понимать, какую проблему они хотят решить, на какие вопросы ответить.
И Data Scientist в этой парадигме — это некоторое наблюдение из нашего распределения Дирихле. Но с помощью этого распределения можно ввести несколько новых должностей, которые будут давать более ясное представление о вашей потенциальной деятельности. Рассмотрим несколько из них.
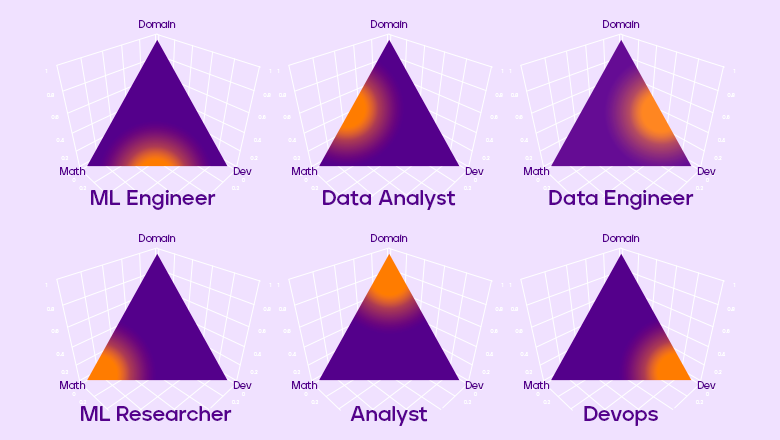
Если вы ищете работу на позицию Machine Learning Engineer, то, скорее всего, будете заниматься введением в эксплуатацию моделей машинного обучения и поддерживать их в актуальном состоянии. Для этого вам потребуются навыки и знания в области алгоритмов машинного обучения, ну и, конечно, разработки.
Если вы аналитик данных, то, вероятно, вы будете заниматься проверкой статистических гипотез, проектировать и проводить эксперименты. Для этого вам требуются фундаментальные знания математической статистики, а также необходимо держать руку на пульсе бизнеса.
Дата-инженер — это человек, который занимается ETL-процессами, архитектурой хранилища, составляет витрины и поддерживает их, организовывает потоковую обработку данных.
Machine Learning Researcher занимается исследовательской работой. Пишет и изучает статьи, придумывает новые математические методы. Таких позиций в России довольно мало, да и встречаются они, как правило, в крупных компаниях, которые могут себе это позволить.
Аналитик — это человек, который отвечает на вопросы бизнеса, и его плотность вероятности приходится на предметную область.
Наконец, DevOps максимально сосредоточен на разработке и развёртывании вашего кода в продакшене.
Требования к специалисту
Специалист по данным неразрывно связан с Data Science – наукой о данных. Она находится на пересечении нескольких направлений: математики, статистики, информатики и экономики. Следовательно, специалисты должны понимать и интересоваться каждой из этих наук.
Кроме этого, Data Scientist должен знать:
- Языки программирования для того, чтобы писать на них код. Самые распространенные – это SAS, R, Java, C++ и Python.
- Базы данных MySQL и PostgreSQL.
- Технологии и инструменты для представления отчетов в графическом формате.
- Алгоритмы машинного и глубокого обучения, которые созданы для автоматизации повторяющихся процессов с помощью искусственного интеллекта.
- Как подготовить данные и сделать их перевод в удобный формат.
- Инструменты для работы с Big Data: Hadoop, MapReduce, Apache Hive, Apache Kafka, Apache Spark.
- Как установить закономерности и видеть логические связи в системе полученных сведений.
- Как разработать действенные бизнес-решения.
- Как извлекать нужную информацию из разных источников.
- Английский язык для чтения профессиональной литературы и общения с зарубежными клиентами.
- Как успешно внедрить программу.
- Область деятельности организации, на которую работает.
Помимо того, что специалист по данным должен обладать аналитическим и математическим складом ума, он также должен быть:
- трудолюбивым,
- настойчивым,
- скрупулезным,
- внимательным,
- усидчивым,
- целеустремленным,
- коммуникабельным.
Хочу отметить, что гуманитариям достичь высот в этой профессии будет крайне тяжело. Только при большом желании можно пробовать осваивать данную стезю.
Подборка хороших курсов
- Практический курс по машинному обучению с менторской поддержкой
- Курс содержит полный обзор современных методов машинного обучения от простых моделей до работы с нейросетями и Big Data от опытного практика области
- Специализация Яндекса и МФТИ на Coursera на русском языке
- Полное введение в data science и машинное обучение на базе Python
- Теорию можно смотреть бесплатно, задания и сертификат — платные
- Интерактивное пошаговое изучение Data Science с фокусом на Python
- Обучение через практику: с самого начала работа с реальными данными и кодом
- 3 направления на выбор: Data Scientist, Data Analyst или Data Engineer
- Интерактивный онлайн-курс по Data Science с фокусом на R
- 66 курсов по машинному обучению, анализу данных и статистике
- Курс построен на решении практических задач
«Специализация Аналитик Данных»
- Специализация включает сквозной курс и тренажёры по инструментам для анализа данных.
- Срок обучения: 6 месяцев
- Онлайн-программа профессиональной переподготовки от Института биоинформатики и Санкт-Петербургского Академического университета РАН, не требующая специальной подготовки
- Срок обучения: 1 год. С лета 2017 — ускоренная программа (полгода)
- Стоимость: 1999 рублей в месяц
Курс по математике для Data Science
Курс содержит много практики, которая не ограничивается решением классических уравнений и абстрактных заданий.
Основы статистики
Бесплатное и ясное введение в математическую статистику для всех
- Легендарный курс основателя Coursera и одного из лучших специалистов по искусственному интеллекту Эндрю Ын (Andrew Ng)
- Этот курс можно считать индустриальным стандартом по введению в машинное обучение
- Добрый человек “перевел” задания на Python (в оригинале нужно все делать на Octave)
- Курс от NVIDIA и SkillFactrory
- Комплексный курс по глубокому обучению на Python для начинающих
- Видеозаписи занятий легендарной Школы анализа данных Яндекса
- Курсы: машинное обучение, алгоритмы и структуры данных, параллельные вычисления, дискретный анализ и теория вероятности и др.
“10 онлайн-курсов по машинному обучению”
Подборка удаленных образовательных программ, составленная проектом “Теплица социальных технологий”
- Любопытное введение в статистику на примере … котиков
- Вы получите знания об основах описательной статистики, дисперсионном и корреляционном анализе
- Фишка курса — наглядность (опять же картинки с котиками)
- Учит извлекать данные из разных файлов, баз данных и API
- Преобразовывать данные для удобного анализа
- Интерпретировать и визуализировать результаты анализа
Курс по Python для анализа данных
Практический курс по Python для аналитиков с менторской поддержкой.
- Курс от Высшей школы экономики
- Онлайн-курс по самому популярному языку программирования для data scientist’ов
Где используется Data Science?
- Как насчет того, сможете ли вы понять точные требования своих клиентов к существующим данным, таким как история просмотра посетителей, история покупок, возраст и доход. Без сомнения, у вас были все эти данные ранее, но теперь с огромным количеством и разнообразием их вы можете более эффективно обучать модели и рекомендовать продукт своим клиентам с большей точностью. Разве это не удивительно, поскольку это принесет больше преимуществ вашей организации?
- Давайте рассмотрим другой сценарий, чтобы понять роль Data Science в принятии решений. Как насчет того, если ваш автомобиль использовал элементы ИИ чтобы отвезти вас домой? Автопилот собирает данные от датчиков, радаров, камер и лазеров, чтобы создать карту окружения. Основываясь на этих данных, он принимает решения, например, когда ускоряться, когда нужно обгонять, где нужно сделать чередование с использованием передовых алгоритмов машинного обучения.
- Давайте посмотрим, как Data Science может использоваться в интеллектуальной аналитике. Рассмотрим пример прогнозирования погоды. Данные о кораблях, самолетах, радарах, спутниках могут собираться и анализироваться для создания моделей. Эти модели не только прогнозируют погоду, но также помогают прогнозировать возникновение любых стихийных бедствий. Это поможет вам заранее принять необходимые меры и спасти много драгоценных жизней.
Посмотрим на нижеприведенную инфографику, чтобы увидеть все области, где Data Science производит впечатляющие результаты.

В каких областях Data Science поражает воображение
Теперь, когда вы поняли необходимость в Data Science, давайте поймем, что это такое.
*2020: Академия больших данных MADE и HeadHunter выяснили, как меняется спрос на Data Scientist в России
16 июля 2020 года Академия больших данных MADE от Mail.ru Group и российская платформа онлайн-рекрутинга HeadHunter (hh.ru) составили портреты российских специалистов по анализу данных (Data Science) и машинному обучению (Machine Learning). Аналитики выяснили, где они живут и что умеют, а также чего ждут от них работодатели и как меняется спрос на таких профессионалов.
Академия MADE и HeadHunter (hh.ru) проводят исследование уже второй год подряд. На этот раз эксперты проанализировали 10 500 резюме и 8100 вакансий. По оценкам аналитиков, специалисты по анализу данных — одни из самых востребованных на рынке. В 2019 году вакансий в области анализа данных стало больше в 9,6 раза, а в области машинного обучения – в 7,2 раза, чем в 2015 году. Если сравнивать с 2018 годом, количество вакансий специалистов по анализу данных увеличилось в 1,4 раза, по машинному обучению – в 1,3 раза.

Активнее других специалистов по большим данным ищут ИТ-компании (на их долю приходится больше трети – 38% – открытых вакансий), компании из финансового сектора (29% вакансий), а также из сферы услуг для бизнеса (9% вакансий).
Такая же ситуация и в сфере машинного обучения. Но здесь перевес в пользу ИТ-компаний еще очевиднее – они публикуют 55% вакансий на рынке. Каждую десятую вакансию размещают компании из финансового сектора (10% вакансий) и сферы услуг для бизнеса (9%).
С июля 2019 года по апрель 2020 года резюме специалистов по анализу данных и машинному обучению стало больше на 33%. Первые в среднем размещают 246 резюме в месяц, вторые – 47.

Самый популярный навык — владение Python. Это требование встречается в 45% вакансий специалистов по анализу данных и в половине (51%) вакансий в области машинного обучения.
Также работодатели хотят, чтобы специалисты по анализу данных знали SQL (23%), владели интеллектуальным анализом данных (Data Mining) (19%), математической статистикой (11%) и умели работать с большими данными (10%).
Работодатели, которые ищут специалистов по машинному обучению, наряду со знанием Python ожидают, что кандидат будет владеть C++ (18%), SQL (15%), алгоритмами машинного обучения (13%) и Linux (11%).
В целом предложение на рынке Data Science соответствует спросу. Среди самых распространенных навыков специалистов по анализу данных – владение Python (77%), SQL (48%), анализом данных (45%), Git (28%) и Linux (21%). При этом владение Python, SQL и Git – навыки, которые практически одинаково часто встречаются в резюме специалистов любого уровня. Опытных специалистов отличают развитые навыки анализа данных, в том числе интеллектуального (Data Analysis и Data Mining).
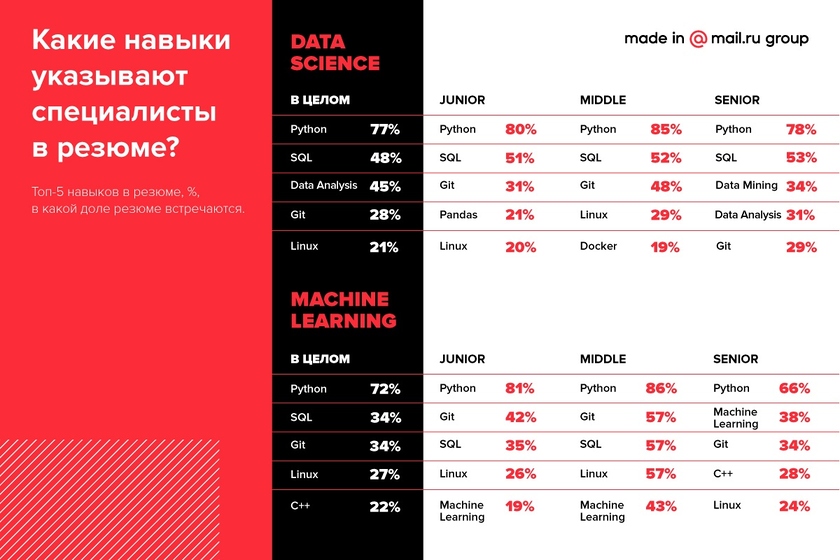
У специалистов по машинному обучению в топе такие навыки, как владение Python (72%), SQL (34%), Git (34%), Linux (27%) и С++ (22%).
На долю Москвы приходится больше половины (65%) вакансий специалистов по в сфере анализа данных и ровно половина вакансий специалистов в области машинного обучения. На втором месте Санкт-Петербург: 15% вакансий специалистов в сфере анализа данных и 18% вакансий в области машинного обучения — в этом городе.
По сравнению с первым полугодием 2019 года в июле 2019 года – апреле 2020 года доля вакансий специалистов по анализу данных в Москве несколько возросла — с 60% до 65%.
Что касается соискателей, больше половины из них также находятся в Москве: 63% специалистов по анализу данных и 53% специалистов по машинному обучению. Вторая строчка – тоже за Санкт-Петербургом (16% и 19% резюме соответственно).
2017: Высшая школа экономики будет обучать Data Culture на всех программах бакалавриата
НИУ ВШЭ первым из российских университетов начнет формировать компетенции по Data Science у всех студентов, обучающихся на программах бакалавриата. В рамках проекта Data Culture расширится набор дисциплин и появятся образовательные треки по анализу больших данных.
Data Culture – это общий термин для обозначения навыков и культуры работы с данными. Высшая школа экономики считает, что запуск проекта, направленного на воспитание у студентов таких навыков, сейчас актуален из-за огромного потенциала использования больших данных и трансформации профессий, которые, так или иначе, используют или могут использовать большие массивы информации. Потребность рынка в специалистах с компетенциями по анализу данных, перерастает в необходимость воспитания во всех предметных областях профессионалов, понимающих возможности и ограничения массивов данных, потенциал и особенности методов машинного обучения, а в ряде направлений и умеющих пользоваться этими технологиями и инструментами.
Проект Data Culture станет продолжением интеграции в образовательные программы НИУ ВШЭ элементов, направленных на воспитание у студентов культуры и умений работы с данными. Он расширит возможности студентов уже абсолютно всех образовательных программ по формированию компетенций, связанных с Data Science. Это позволит выпускникам в перспективе быстро и эффективно интегрироваться в решение профессиональных задач на стыке предметных областей и компьютерных технологий, которые сегодня являются передовыми, но уже в ближайшей перспективе станут привычной практикой.
Проект включает разработку отдельных курсов по Data Science так или иначе кастомизированных под специфику образовательных программ, а также формирование специализированных образовательных треков из таких курсов с разной степенью сложности: начального, базового, продвинутого, профессионального и экспертного уровней. Это связано с большим разнообразием образовательных программ, студенты которых дифференцированы по базовым компетенциям в сфере математики и информатики. Для программ или их блоков будет предложена система курсов Data Culture в определенной вилке «сквозного уровня продвинутости». Более того, эти системы курсов определятся спецификой предметных областей.
Внедрение дисциплин Data Culture будет происходить поэтапно. В 2017/2018 учебном году будут включены в учебные планы обязательные и элективные курсы по направлению Data Science для части образовательных программ, но таковых будет более половины. Например, у студентов-гуманитариев, юристов и дизайнеров появится вводный курс по цифровой грамотности, программы экономистов дополнятся дисциплиной по машинному обучению, политологов – анализу социальных сетей, у статистиков появится курс по программированию и извлечению и анализу интернет-данных. С 2018 года к проекту примкнут все образовательные программы.
Для реализации проекта Data Culture предполагается привлечение преподавательского состава как из академической среды (преподаватели факультета компьютерных наук, сотрудники департамента математики факультета экономических наук и общеуниверситетской кафедры высшей математики и т.д.), так и из индустрии (участники сообществ по анализу данных, участники тематических мероприятий по анализу данных, проводимых в IT-компаниях). Более того, преподаватели факультетов, которые уже погружены в работу с данными в рамках своей профессиональной деятельности, также будут разрабатывать курсы в рамках проекта Data Culture для студентов своих и смежных факультетов.
